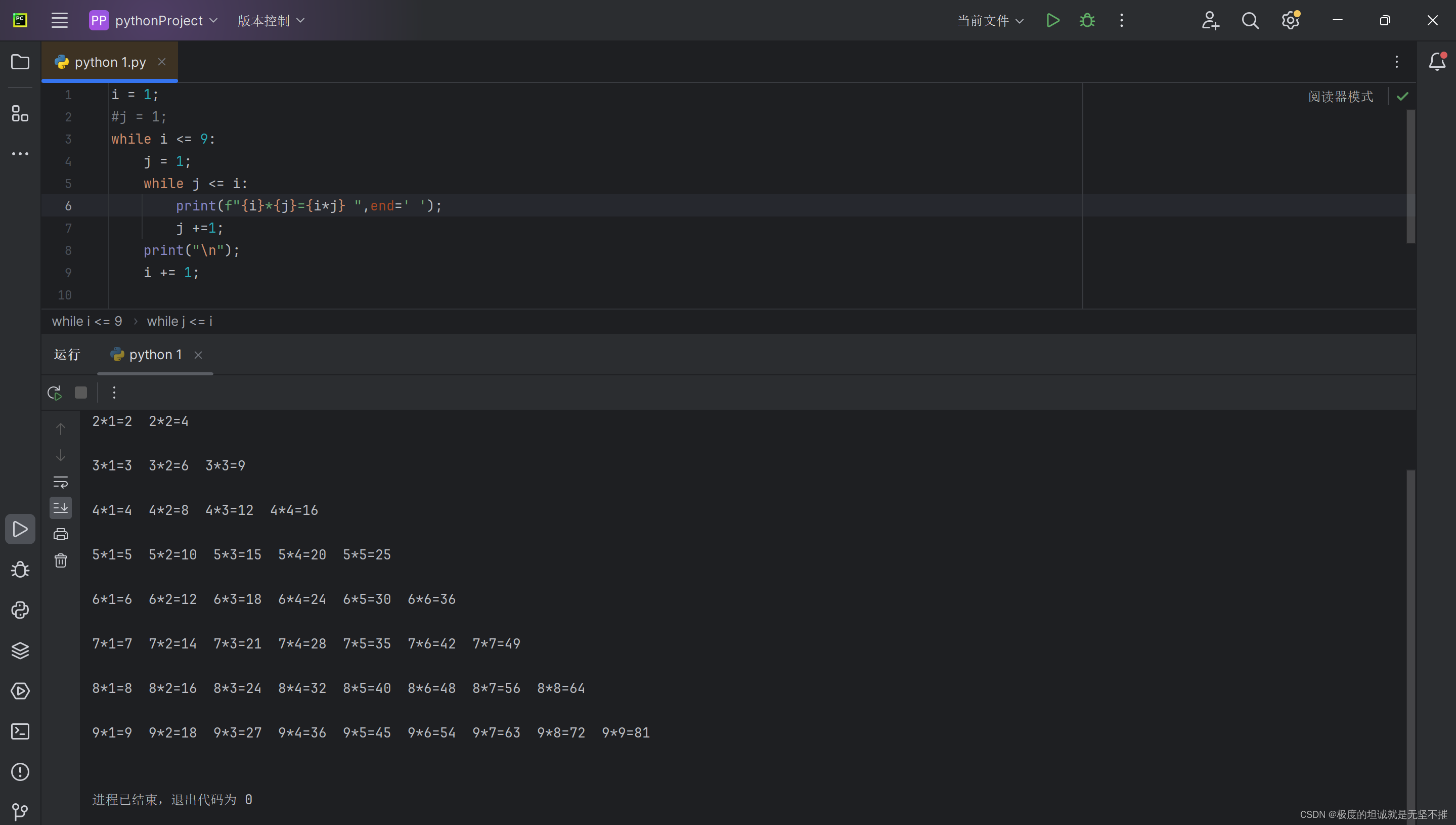
直接运行即可爬取网页云某歌单的歌曲
"""
程序目标是下载当前页面中所有的歌曲。
通过接口下载: 接口链接 + 歌曲ID
"""
import os
import time
import requests
from lxml import etree
# 1、定义请求头
headers = {
'User-Agent': 'Mozilla/5.0'
}
# 2、定义网易云歌单的网址(记得删除/#,否则请求到的不是真是的网页)
url = 'https://music.163.com/playlist?id=934870683'
# 3、发起网络请求,获取网页中的数据
response = requests.get(url, headers=headers)
# print(response.text)
# 4、将网页的html数据(字符串)转换为树形结构
html = etree.HTML(response.text)
# 5、筛选目标数据(歌曲ID和名称)
music_label_list = html.xpath('//a[contains(@href,"/song?")]')
print(music_label_list)
# 可以使用os库来新建文件夹
if not os.path.exists('music'):
os.mkdir('music')
# 6、对标签列表进行循环遍历,得到单首歌曲的标签信息
for music_label in music_label_list:
# 从单个的音乐标签中筛选出ID信息
href = music_label.xpath('./@href')[0]
# print('href数据:', href)
# 从ID信息中切割出ID的数字值
#元素示例:<a href="/song?id=1823305772">
music_id = href.split('=')[1]
# print('ID数据:', music_id)
# 判断字符串中是否是数字(如果是数字结果才为真)
if music_id.isdigit():
# 这是正确的歌曲ID
print('ID数据:', music_id)
# 提取出歌曲的名字
music_name = music_label.xpath('./text()')[0]
print('歌曲名字:', music_name)
# 定义请求歌曲的链接
music_url = 'http://music.163.com/song/media/outer/url?id=' + music_id
# 发送网络请求获取歌曲数据
response = requests.get(music_url, headers=headers)
# 将歌曲数据保存到mp3文件中
with open(f'./music/{music_name}.mp3', 'wb') as file:
file.write(response.content)
print(f'《{music_name}》下载成功。。。。。。')
# 下载一首歌后延时1秒
time.sleep(1)
# 6、对标签列表进行循环遍历,得到单首歌曲的标签信息
for music_label in music_label_list:
# 从单个的音乐标签中筛选出ID信息
#. 代表当前节点。
#@href 代表 href 属性。
#[0] 用于获取列表中的第一个元素。在 lxml 库中,xpath 表达式通常会返回一个列表,即使只匹配到一个元素。通过在表达式后面添加 [0],你可以从返回的列表中获取第一个元素。这对于只需要单个值的场景非常有用。
href = music_label.xpath('./@href')[0]





![[PyTorch]:加速Pytorch 模型训练的几种方法(几行代码),最快提升八倍(附实验记录)](https://img-blog.csdnimg.cn/img_convert/145c4c5115995c7a98da0293ede96bc9.png)